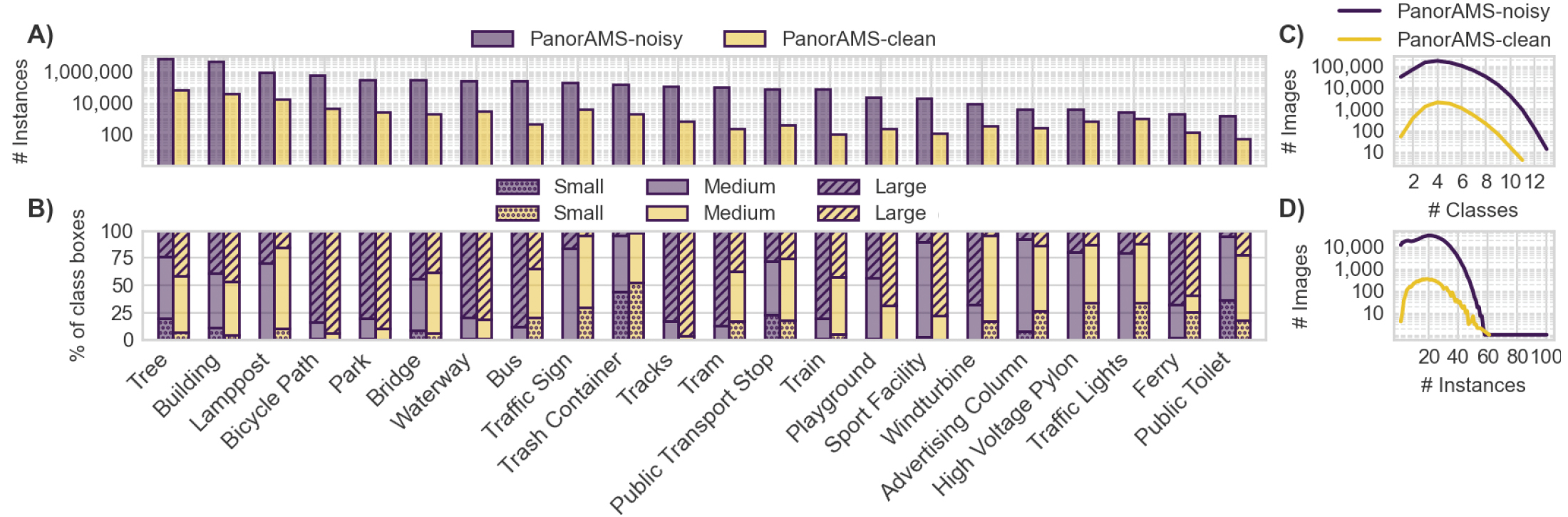
The PanorAMS framework involves a method to automatically generate bounding box annotations in geo-referenced panoramic images based on geospatial context information. Following this method, we acquire large-scale (albeit noisy) annotations solely from open data sources in a fast and automatic manner. For detailed evaluation, the framework includes an efficient protocol (using the generated boxes as a starting point) to crowdsource groundtruth annotations for a subset of the images.
23/09/2024
PanorAMS datasets available online
06/06/2023
Paper published in
IEEE Transactions on Multimedia
06/03/2023
Website live
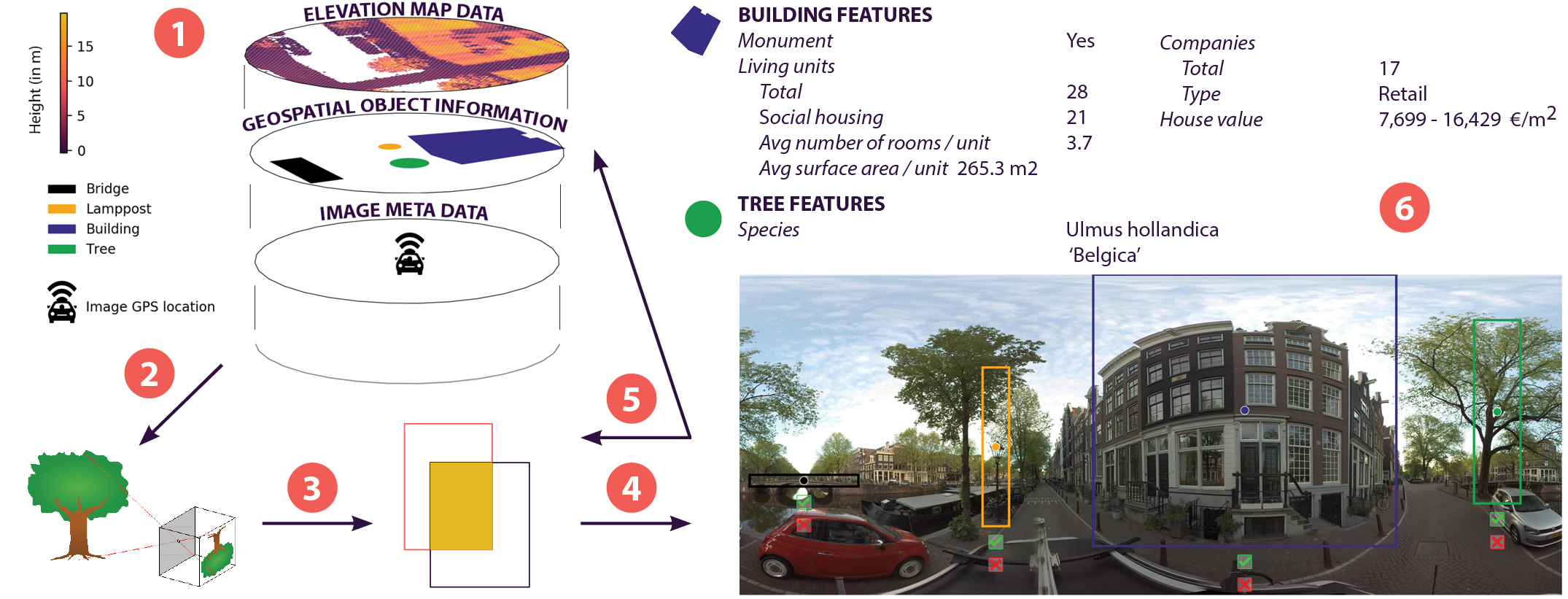 Our step-by-step method to use geospatial context information to automatically generate bounding box
annotations in geo-referenced panoramic images:
Our step-by-step method to use geospatial context information to automatically generate bounding box
annotations in geo-referenced panoramic images:
 To evaluate the quality of our automatically generated bounding boxes, we crowdsource ground-truth
annotations for a subset of the images contained in PanorAMS-noisy. For
this, we implement an efficient crowdsourcing protocol using
the generated boxes as a starting point. In the interest of minimizing the
required annotation time, the user interface of our crowdsourcing tool
is
built such that the necessary mouse and eye movements are kept to a minimum. Our crowdsourcing protocol
is subdivided
into three tasks in order to avoid task-switching, which is
well-known to increase response time and decrease accuracy. We introduce
the concept of linked bounding boxes that is specific to objects
split across the left and right side of 360° images, whereby two
bounding boxes are labeled as belonging to the same object. The image depicts two active linked
boxes, ready to be broken up (by clicking the linkage button below the left
active box), corrected (by dragging the middle point and borders of the active
box) or deleted (by clicking the red X mark button) as need be. The linkage
icon in the middle of the screen informs the user that there are two active
linked boxes. The boxes can be verified by clicking the green check mark
button. The orange color is specific for the playground class.
To evaluate the quality of our automatically generated bounding boxes, we crowdsource ground-truth
annotations for a subset of the images contained in PanorAMS-noisy. For
this, we implement an efficient crowdsourcing protocol using
the generated boxes as a starting point. In the interest of minimizing the
required annotation time, the user interface of our crowdsourcing tool
is
built such that the necessary mouse and eye movements are kept to a minimum. Our crowdsourcing protocol
is subdivided
into three tasks in order to avoid task-switching, which is
well-known to increase response time and decrease accuracy. We introduce
the concept of linked bounding boxes that is specific to objects
split across the left and right side of 360° images, whereby two
bounding boxes are labeled as belonging to the same object. The image depicts two active linked
boxes, ready to be broken up (by clicking the linkage button below the left
active box), corrected (by dragging the middle point and borders of the active
box) or deleted (by clicking the red X mark button) as need be. The linkage
icon in the middle of the screen informs the user that there are two active
linked boxes. The boxes can be verified by clicking the green check mark
button. The orange color is specific for the playground class.